|
I'm a data scientist who's been working with data for more than eight years. I love to solve business problems and automate business processes by leveraging data and technology. I love to share my data science knowledge through platforms like Kaggle, Medium, Tableau Public and GitHub. My interests lie in GenAI, Machine learning, Deep learning, NLP, Statistics, Time series forecasting, Data analysis, Data visualization, Data driven decision making, Web scraping, Process automation and big data analytics with PySpark. Currently I'm exploring GenAI, advanced NLP, MLOps and Big Data Engineering.
MRAG is a no-code platform to build RAG pipelines and chat with your documents. Its features include:
- Provides an interactive QA chatbot with voice support where a user can also see the retrieved context to verify the response.
- Provides options for query enrichment like splitting a user query into sub queries, rewriting the user query for better retrieval, clean a user query
and self querying to pre-filter documents using their metadata.
- Displays evaluation metrics like answer relevance socre and reponse hallucination score for each response of the user's query.
- Enables context enrichment by generating Hypothetical Prompt Embeddings (HyPE) where hypothetical queries are generated from documents using an LLM and the
embeddings of the questions are stored in vector index resulting in a query-to-query comparison for context retrieval.
- Provides multiple document splitters like Token Splitter, Sentence Splitter, Regex Splitter, PDF Font Splitter and Dummy Splitter.
- Provides metadata extractor for the user to define metadata schema to extract metadata from documents using regular expressions.
- User can customize QA chatbot settings like LLM, temperature, retriever settings, hybrid search settings and re-ranking settings.
- Provides document and chunk viewer to preview the raw document text and chunks generated by splitters.
News aggregator is an AI-powered app that aggregates news from a few selected RSS news feeds. The details of the backend services are given below:
- News indexing service: Extracts news items from a list of RSS feeds, computes the sentence embeddings using sentence transformers and stores the embeddings in Milvus vector database for content-based recommendations using semantic search.
- Embedding deletion service: Articles and their embeddings older than a month are deleted from Milvus vector database.
- ETL service: Extracts news items from a list of RSS feeds in parallel using multiprocessing.
The news items are processed and the categories of the news items are
predicted using DistilBERT model that is
fine-tuned (full fine-tuning) on
news article headline classification task, the model is then quantized using TFLite. Top 5 similar news articles are identified from Milvus vector database using cosine similarity.
The similar articles are then reranked using cross encoders. News articles are summarized using
BART model that is fine-tuned on CNN and Daily Mail news articles. The transformed data is loaded into MongoDB Atlas (MongoDB-as-a-service).
The backend services are periodically triggered using a CRON job scheduled using GitHub Actions.
The front end service reads the data from MongoDB Atlas and renders it in HTML when a user invokes it.
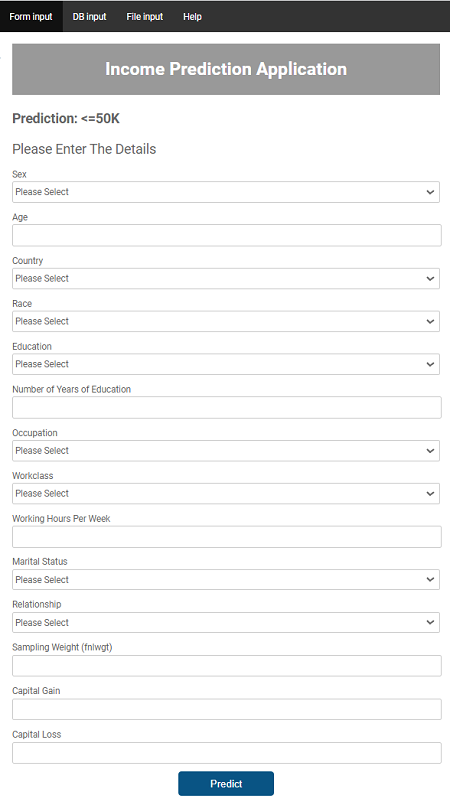
This project demonstrates the development of a production-grade end-to-end binary classification application. The process of developing the application is as follows:
* Data is ingested from a database, validated and cleaned.
* Data is preprocessed by removing id variables, variables with low variance,
winsorizing outliers, imputing missing values, removing correlated features, marking rare categories, one-hot encoding, ordinal encoding and scaling. The hyperparameters of
preprocessing steps are tuned using Hyperopt while training.
* New features are constructed as part of feature construction step.
* Data is clustered and clusters are added as features to data. Best 'k' is found using silhouette score.
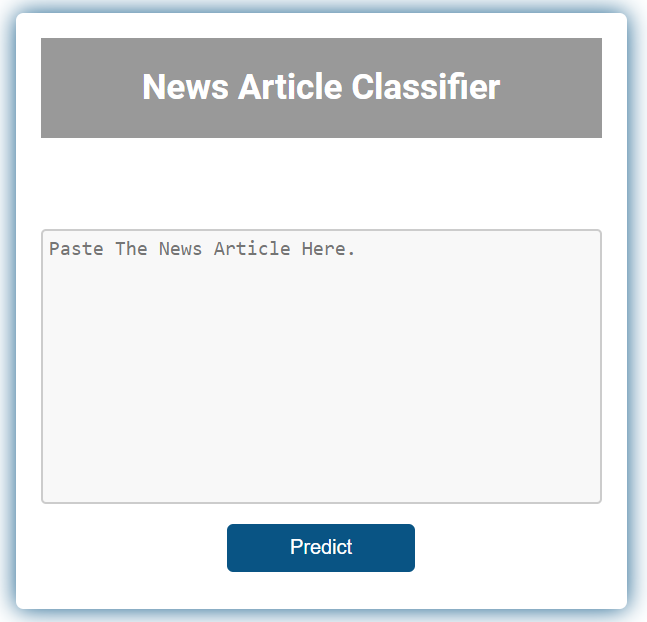
This project demonstrates the development of a production-grade end-to-end multi-class text classification application using a small and imbalanced dataset. News Article Classifier classifies a news article into sport, entertainment, politics, tech and business classes. The model is trained on 1,500 BBC news articles. The data is augmented (using nlpaug) to increase the size of the dataset by 35X. The text is vectorized using Google Word2Vec and its dimension is reduced using PCA. Multiple machine learning models were auto tuned using Hyperopt to find the best performing model. The ML model is served as an API developed using FastAPI. The front-end application makes an API call upon a user request. Both API and front-end application are dockerized and deployed as individual web services to render.com.

The project uses TensorFlow to fine-tune HuggingFace models for various tasks like text classification, text summarization and text translation. The models are fine-tuned for the following tasks:
- Text classification using DistilBERT.
- Text summarization using T5.
- Translation from English to French using T5.
- Translation from English to Hindi using ByT5.
- Text embedding extraction from DistilBERT and RoBERTa.
- Text classification using RoBERTa.
- Text classification using ALBERT & XAI with LIME.
- Hindi text summarization using mT5.
- Text summarization using Bard.
- Named entity recognition using DistilBERT and DeBERTa.

The project fine-tunes YOLO for object detction tasks like:
- Vehicle Number Plate Recognition
- Credit Card Detection & OCR
- Face Detection
It is an auto EDA package to perform basic exploratory data analysis. The package enables user to derive data structure summary, get summary of categorical and numeric attributes, plot correlation matrix, derive chi-square test results, generate plots between different attribute types, identify mutual information and multicollinearity.

Machine learning algorithms, data preprocessing functions, cross-validation functions developed from scratch using Python.
- ML algorithms from scratch
- Data preprocessing functions from scratch
- Cross-validation functions from scratch

This project demonstrates the process of preprocessing and incrementally training SGD classifer on a dataset having ~33.5M samples and 23 features (~9.5 GB in size). Parallelizing the EDA and data preprocessing tasks using multiprocessing package. Reducing the dimensionality using IncrementalPCA.
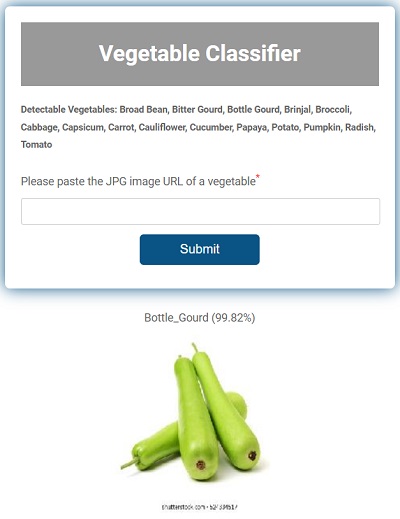
This project classifies the uploaded color images of vegetables into 15 classes. The model is trained using transfer learning technique (MobileNet-v2) and is quantized using TensorFlow Lite which resulted in 5x reduction in model size. The training dataset contained 15,000 (1,000 per class) vegetable images captured by a mobile phone camera.
This project forecasts the hourly electricity consumption using LSTM model.
This package enables a user to export Excel or CSV files to MySQL. This package automatically parses the data types. Creates a new database with the specified name or uses the existing one. Creates a new table with the specified name or uses the existing one. Inserts all the records from the specified CSV/Excel into the table.